Further, we show that MacroF1 can be used to effectively compare supervised and unsupervised neural machine translation, and reveal significant qualitative differences in the methods' outputs.
Collaborators: Weiqiu You, Constantine Lignos, and Jonathan May
Abstract
We explore the simple type-based classifier metric, MacroF1, and study its applicability to MT evaluation. We find that MacroF1 is competitive on direct assessment, and outperforms others in indicating downstream cross-lingual information retrieval task performance. Further, we show that MacroF1 can be used to effectively compare supervised and unsupervised neural machine translation, and reveal significant qualitative differences in the methods' outputs.
Links
DOI (To Appear at NAACL 2021)
Code
MacroF1 code is in a fork of sacrebleu https://github.com/isi-nlp/sacrebleu
Pull request is submitted to sacrebleu
Usage of MacroF1 and MicroF1:sacrebleu $REF.txt -m macrof < $HYP.detok sacrebleu $REF.txt -m microf < $HYP.detok
Video
Summary
In the previous work, we framed NMT as a multi-class classifier. In this work, we evaluate NMT (or MT, NLG in general) as if it is a multi-class classifier. The overall performance of a multi-class classifier is commonly obtained by taking an average of individual class performances. Two common ways to compute averages are Micro- and Macro- averages. In many tasks used by academia, test set classes are often balanced, and in those scenarios micro and macro are essentially equivalent. However, if the test set classes are imbalanced, which is likely the case in real-world, micro and macro averages make a huge difference depending on the degree of imbalance.
In NLP/linguistic terms, micro average assigns equal weight to each token (or instance), whereas macro-average assigns equal weight to each type (or class). Since the types in natural language datasets resemble Zipfian distribution, an extremely imbalanced distribution, reporting micro-averaged performance would be misleading, especially because minority classes (i.e rare types) are equally or more important than majority classes (aka stop words).
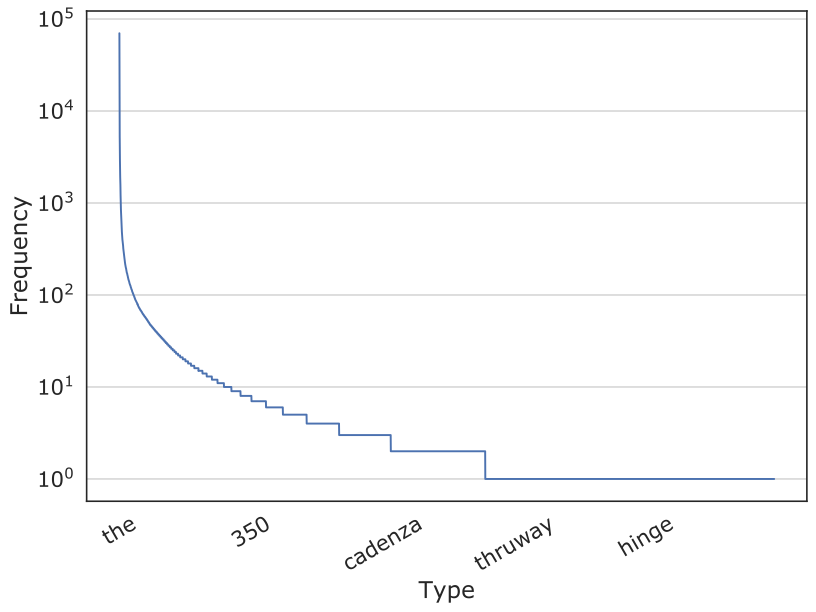
Do we really need one more MT evaluation metric? What is wrong with the current metrics that needs to be addressed? BLEU[1], ChrF[2], and such model-free metrics that are in use today are micro-averaged metrics — they treat each token equally. As a result, they provide higher rewards for learning stopword types like if, and, and but, and significantly less reward for learning to generate content words like xylophone, peripatetic, and defenestrate. In other words, when we measure using micro-averaged metrics the improvements in translating content words better than baselines, we see the delta compared to baseline is so tiny; we tend to believe that the improvements are not significant. And we risk in discarding good ideas because the micro-averaged metrics marginalize rare types.
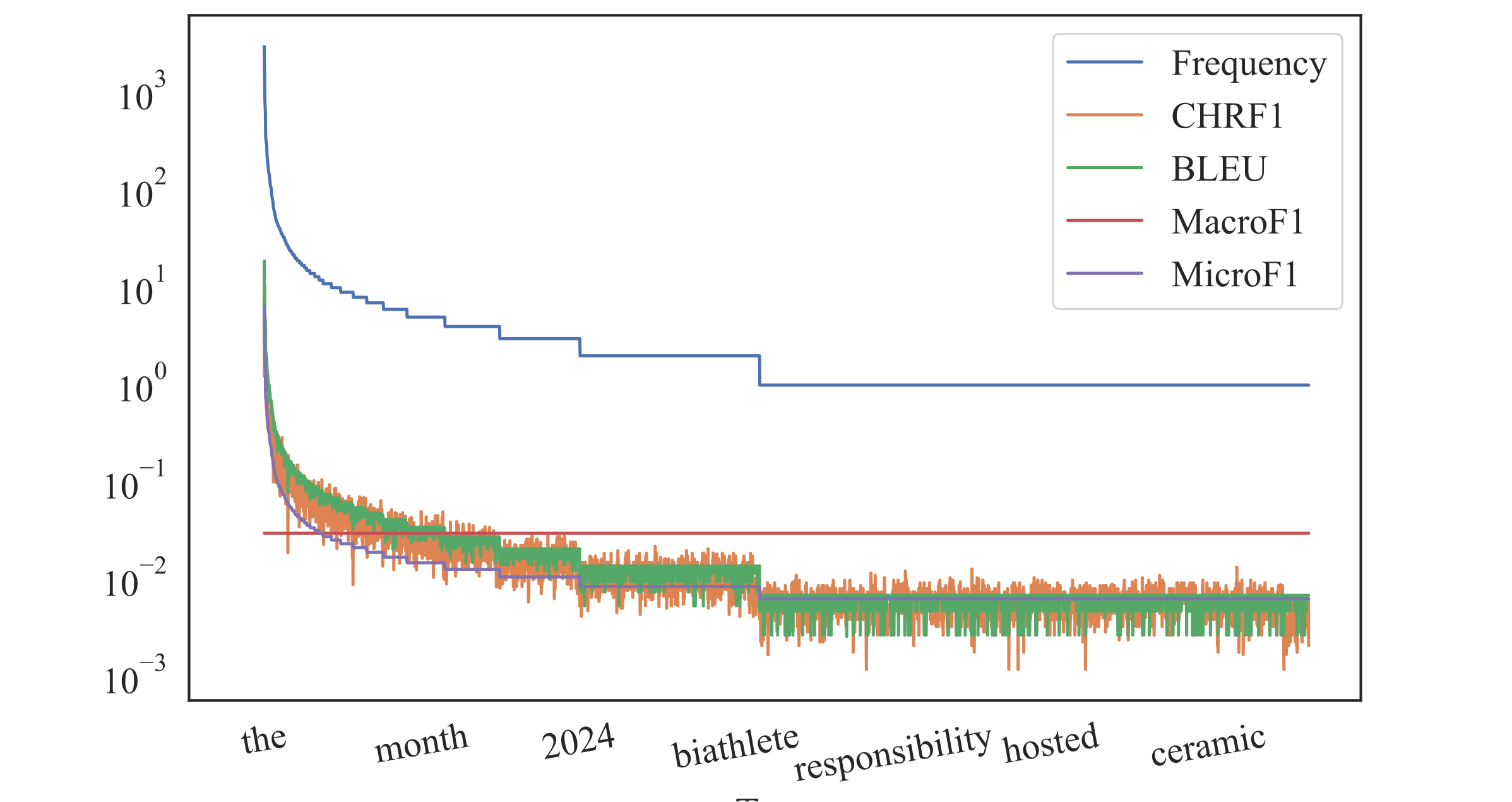
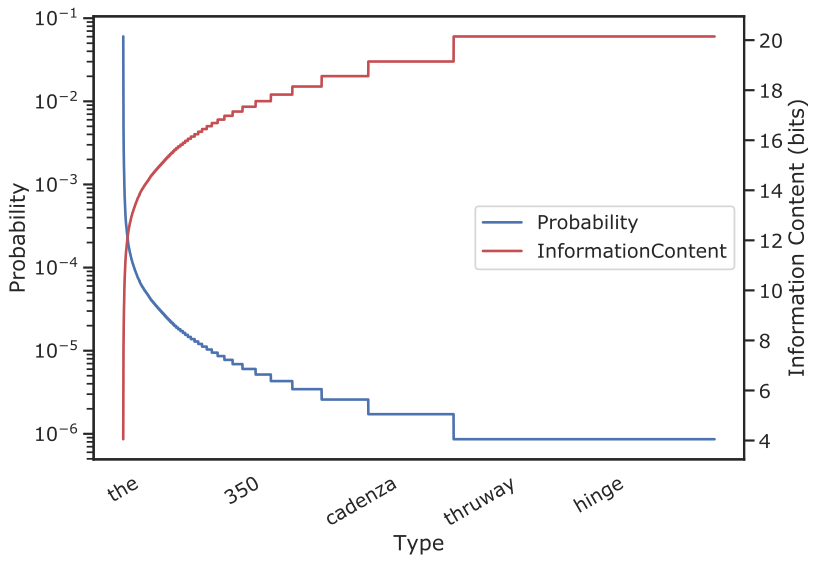
But in reality, these low frequency content types carry a lot of information (isnt it why they called content words?). Information theory also agrees with this statement
On the other hand, a lot of model-based evaluation metrics have been proposed lately. These high performance models are opaque, expensive, and biased in several undesirable ways. For example, we looked into BLEURT[3], one of the best model-based metrics at the time of writing, and it showed preferences on certain names in an undesirable ways. In addition, the scores are not really interpretable.
Reference: | You must be a doctor. | |
Hypothesis: | __ must be a doctor. | |
He | -0.74 | |
Joe | -0.98 | |
Sue | -1.04 | |
She | -1.10 | |
Reference: | It is the greatest country in the world. | |
Hypothesis: | __ is the greatest country in the world. | |
France | -0.02 | |
America | -0.06 | |
Russia | -0.16 | |
Canada | -0.31 | |
Will a simple metric like MacroF1 be competitive for MT evaluation? We have been very skeptical too. So we’ve tested it thoroughly on several tasks, which are as follows:
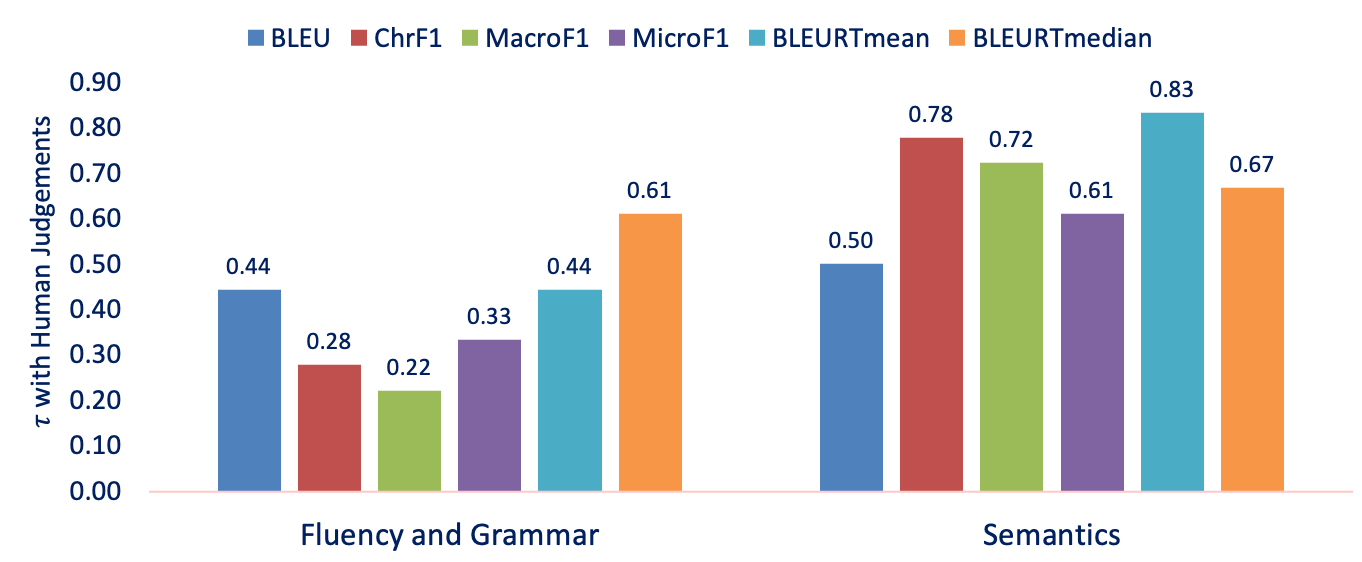
On WebNLG dataset[4] which has human annotations for fluency, grammar, and semantics, MacroF1 found to be a weak indicator of fluency and grammar, but a strong indicator of semantics. Even ChrF1 has a similar property: a weak indicator of fluency and grammar compared to BLEU, but a strong indicator of semantics. Since MicroF1 weighs towards frequent types that contribute to fluency and grammar, it scores relatively higher in fluency compared to MacroF1 but relatively lower on semantics.
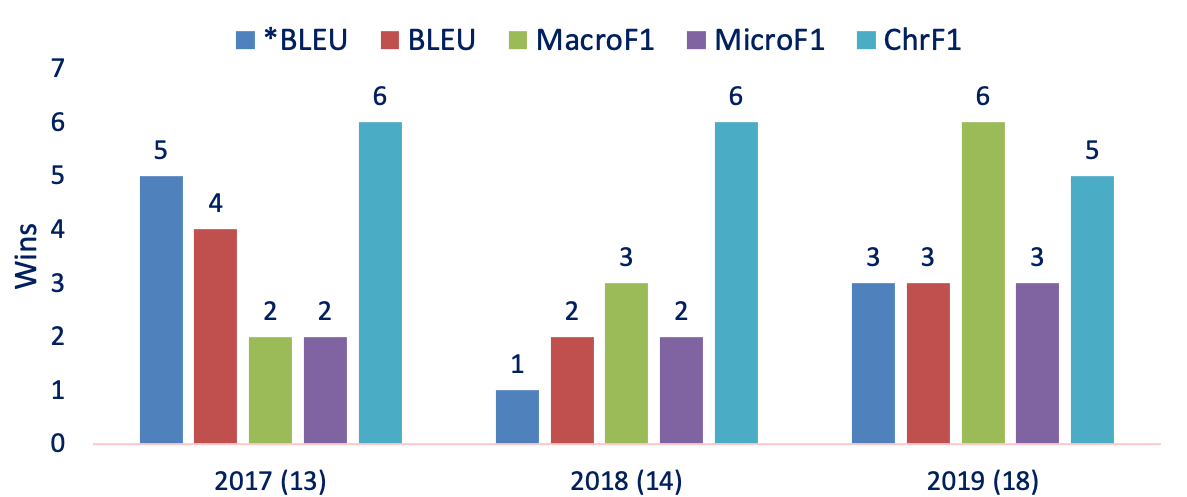
WMT Metrics[5] datasets have human judgements for tens of languages. Here MacroF1 rarely scored the best correlations in 2017. It got better in 2018. And, it scored the highest number of wins per metric in 2019. This trend is interesting; especially if you wonder how a metric that is a poor indicator of fluency and grammar (as seen on our findings on WebNLG datasets) can get such good results on the most recent WMT Metrics Task? We believe NMT models have made great progress in the recent years. The latest models can produce very fluent translations. Now we are in the era where semantics is a key discriminating factor. MacroF1 can capture adequacy better than alternatives.
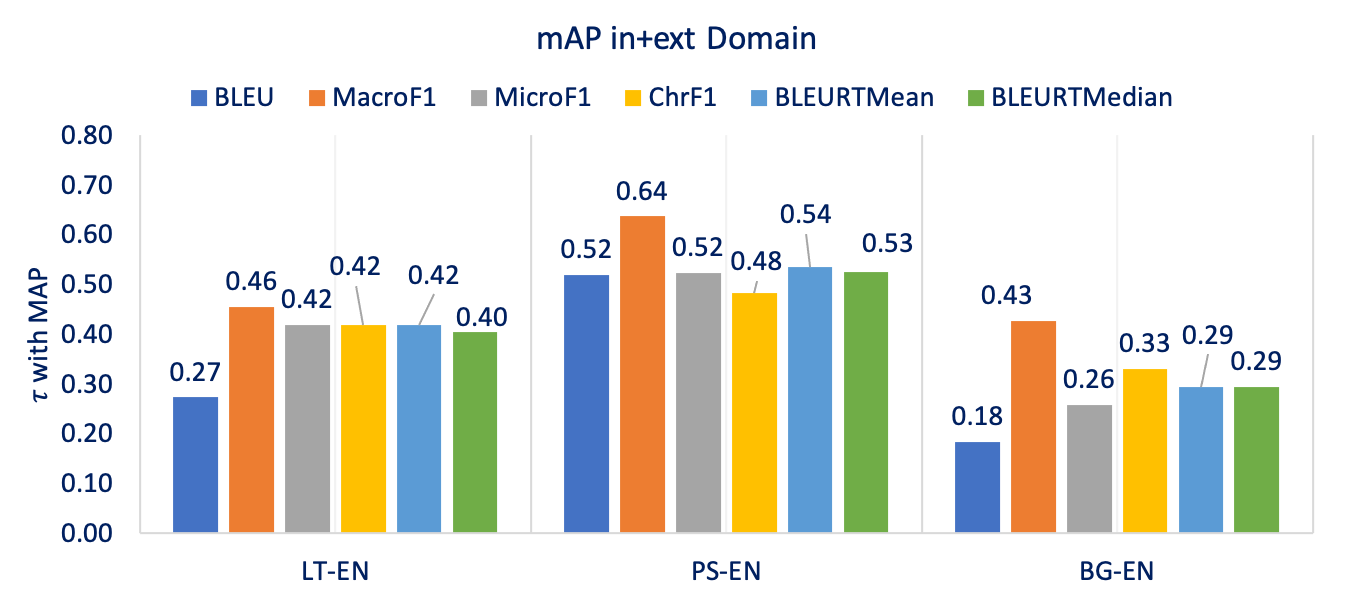
We also tested MT metrics on downstream task of cross-lingual information retrieval (CLIR). This task focused more adequacy and less on fluency. We used CLSSTS 2020 datasets[6] for Lithuanian-English, Pashto-English, and Bulgarian-English and mesaured the IR performance using mean average precision (mAP). This is an IR task in which queries are in English but documents are in foreign languages. MacroF1 found to be the strongest indicator of IR task performance.
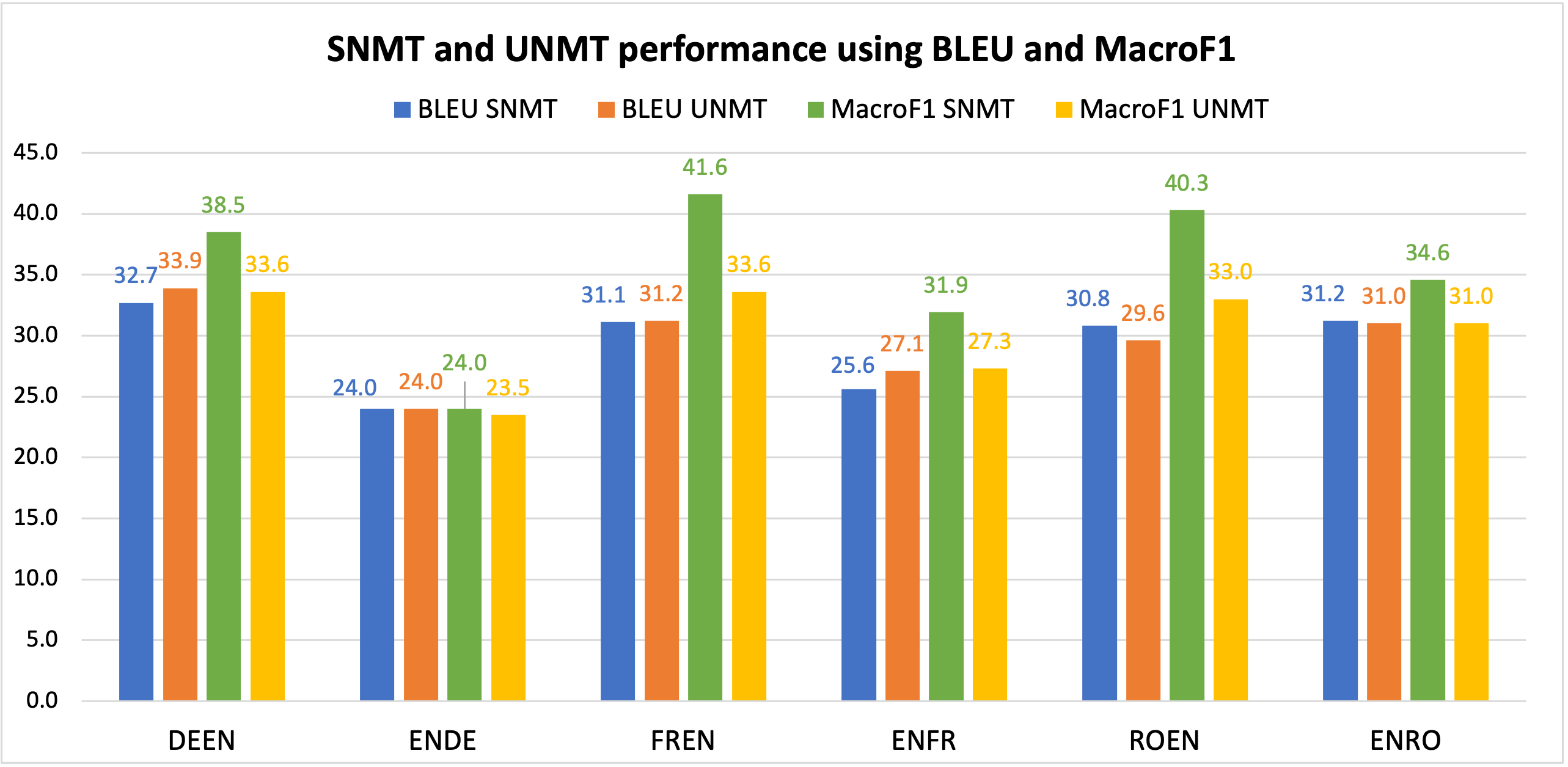
Next, we used MacroF1 to analyse the differences between unsupervised (UNMT) and supervised NMT (SNMT). In the recent years, UNMT has shown very promising results. In many cases, UNMT has shown to achieve BLEU scores comparable with SNMT models. So we took a bunch of UNMT and SNMT models that have comparable BLEU scores and looked at their MacroF1 scores. Even though UNMT models have a comparable BLEU scores they are lagging behind SNMT by considerable margin in terms of MacroF1.
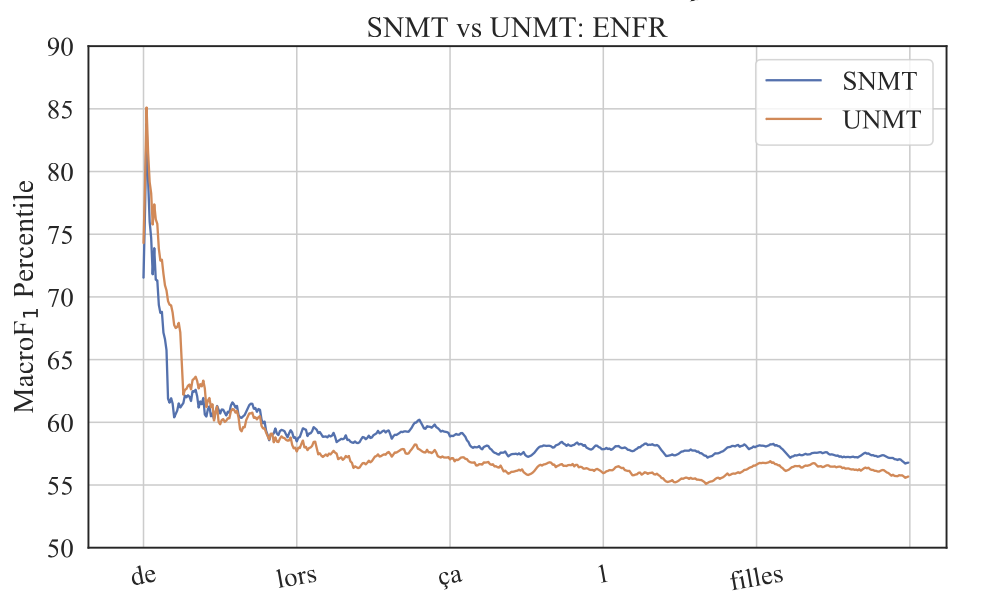
As an added bonus, MacroF1 score can be broken down into individual type/class F1 scores. We looked at how the performance varies across all the types in vocabulary. On high frequency types, UNMT models are relatively better (i.e. better F1 score) than SNMT, which results in fluent outputs, hence good BLEU scores, but UNMT is relatively poorer in translating low frequency types, hence lower MacroF1 than SNMT.
To learn more about this work, please refer to our paper. Send any questions to tg(at)isi.edu.
Citation
@inproceedings{gowda-etal-2021-macro,
title = "Macro-Average: Rare Types Are Important Too",
author = "Gowda, Thamme and
You, Weiqiu and
Lignos, Constantine and
May, Jonathan",
booktitle = "Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies",
month = jun,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.naacl-main.90",
doi = "10.18653/v1/2021.naacl-main.90",
pages = "1138--1157",
}Acknowledgements
Thanks to Shantanu Agarwal, Joel Barry, and Scott Miller for their help with CLSSTS CLIR experiments, and Daniel Cohen for the valuable discussions on IR evaluation metrics.
References
Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. 2002. Bleu: a Method for Automatic Evaluation of Machine Translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics. AssociationforComputationalLinguistics,Philadelphia,Pennsylvania,USA,311–318. https://doi.org/10.3115/1073083.1073135
Maja Popović. 2015. ChrF: Character n-gram F-score for automatic MT evaluation. In Proceedings of the Tenth Workshop on Statistical Machine Translation. Association for Computational Linguistics, Lisbon, Portugal, 392–395. https://doi.org/10.18653/v1/W15-3049
Thibault Sellam, Dipanjan Das, and Ankur Parikh. 2020. BLEURT: Learning Robust Metrics for Text Generation. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Association for Computational Linguistics,Online,7881–7892. https://www.aclweb.org/anthology/2020.acl-main.704 https://github.com/google-research/bleurt
Claire Gardent, Anastasia Shimorina, Shashi Narayan, and Laura Perez-Beltrachini. 2017. Creating Training Corpora for NLG Micro-Planners. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume1:LongPapers).AssociationforComputationalLinguistics,179–188. https://doi.org/10.18653/v1/P17-1017 https://gitlab.com/webnlg/webnlg-human-evaluation
Qingsong Ma, Johnny Wei, Ondřej Bojar, and Yvette Graham. 2019. Results of the WMT19 Metrics Shared Task: Segment-Level and Strong MT Systems Pose Big Challenges. In Proceedings of the Fourth Conference on Machine Translation (Volume 2: Shared Task Papers, Day 1). Association for Computational Linguistics, Florence, Italy, 62–90. http://www.aclweb.org/anthology/W19-5302 http://www.statmt.org/wmt19/metrics-task.html
Ilya Zavorin, Aric Bills, Cassian Corey, Michelle Morrison, Audrey Tong, and Richard Tong. 2020. Corpora for Cross- Language Information Retrieval in Six Less-Resourced Languages. In Proceedings of the workshop on Cross-Language Search and Summarization of Text and Speech (CLSSTS2020). European Language Resources Association, Marseille, France, 7–13. https://www.aclweb.org/anthology/2020.clssts-1.2 http://users.umiacs.umd.edu/~oard/clssts/